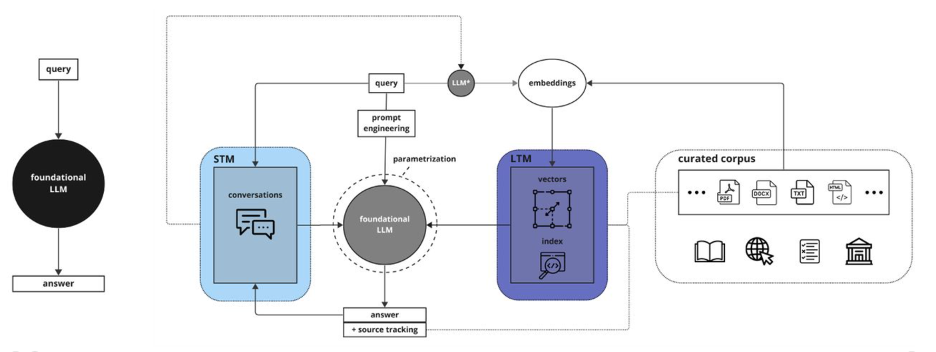
The HPAI domain-specific healthcare model architecture consists of several key components that work together to generate highly accurate outputs of cardiovascular medical information and recovery education for clinicians and patients. Let’s break down each step in the pipeline workflow:
1.
Query: A clinician or patient inputs a query related to a specific cardiovascular health issue or patient case.
2.
STM (Short-Term Memory): The query is first processed by the Short-Term Memory component, which includes two sub-components:
a. Conversations: This module maintains a conversational context, allowing the model to understand the query within the larger scope of the ongoing interaction with the clinician.
b. Prompt Engineering: The query is then refined and optimized through prompt engineering techniques to ensure it is well-structured and clear for the subsequent components.
3.
Foundational LLM: The engineered prompt is passed to the Foundational Large Language Model (LLM), which has been pre-trained on a vast amount of general language data. This LLM provides the underlying language understanding and generation capabilities for the HPAI model.
4.
Parametrization: The output from the Foundational LLM undergoes parametrization, which involves adjusting various parameters to fine-tune the model’s behavior and align it with the specific requirements of the cardiovascular health domain.
5.
LTM (Long-Term Memory): The parametrized output is then processed by the Long-Term Memory component, which consists of two sub-components:
a. Vectors: The output is transformed into high-dimensional vector representations that capture the semantic meaning and relationships within the medical information.
b. Index: These vector representations are stored in an index, which allows for efficient retrieval of relevant content based on the clinician’s query.
6.
Embeddings: The indexed vector representations are used to generate embeddings, which are compact, dense representations of the medical knowledge contained in HPAI’s curated corpus.
7.
Curated Corpus: HPAI’s curated corpus is a carefully selected collection of authoritative cardiovascular health information, compiled in collaboration with the American College of Cardiology (ACC), the National Institutes of Health (NIH), and the National Library of Medicine (NLM). This corpus also includes medical product-specific patient guides, documentation, and pharmaceutical data from reputable pharmaceutical and medical device manufacturers. By training exclusively on this validated content, HPAI ensures that its generated outputs align with the latest evidence-based guidelines and best practices in cardiovascular medicine.
8.
Answer and Source Tracking: The embeddings are used to retrieve the most relevant information from the curated corpus, which is then used to generate a final, accurate answer to the clinician’s query. The source tracking component ensures that the generated output can be traced back to the specific sources within the curated corpus, providing transparency and accountability.
The STM and LTM components play crucial roles in this architecture. The STM helps maintain conversational context and optimize the query through prompt engineering, while the LTM transforms the output into vector representations and indexes them for efficient retrieval. Parametrization allows for fine-tuning the model’s behavior to suit the specific needs of the cardiovascular health domain.
By leveraging this architecture and pipeline, HPAI can generate highly accurate and reliable outputs for clinicians and patients, drawing from a carefully curated corpus of trusted medical knowledge. This helps patients make informed decisions and improves the overall quality of patient outcomes in the field of cardiovascular health.